01
PostgreSQL
Relational Data Model
Normalized schema design following 3NF principles
Schema Design
6 normalized tables with proper foreign key relationships maintaining referential integrity across the dataset.
- Users - Author profiles & flair
- Subreddit - Community metadata
- Post - Post-level data
- Post_Link - Post references
- Comment - All comments with scores
- Moderation - Moderation actions
Key Features
- Automatic Kaggle dataset download
- Streaming SQLite ingestion
- Batch processing (10K records)
- Progress tracking & error handling
- Foreign key constraint validation
- Sample mode for testing
Load Data Command
python load_data.py \
--input database.sqlite \
--host localhost \
--port 5432 \
--user postgres \
--password yourpass \
--dbname redditdb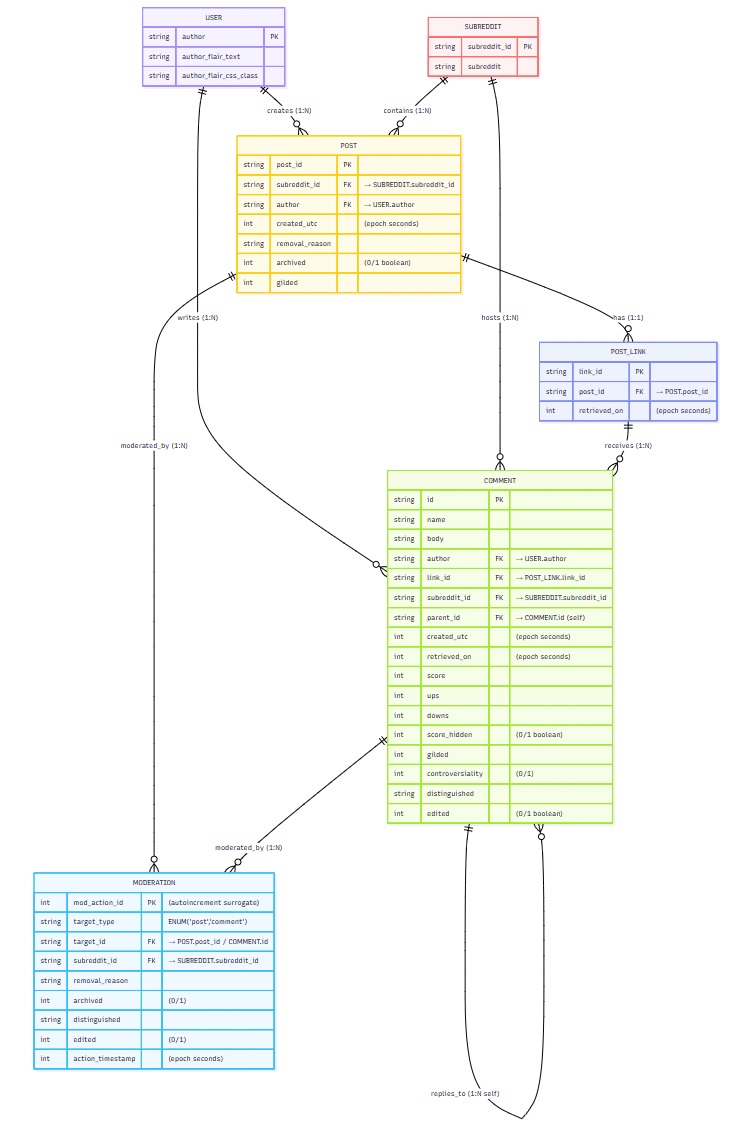
Click to enlarge